

Далее текст от лица автора
9 паттернов сканирования взглядом, 10 способов сделать текст максимально удобным для восприятия
Мы пишем тексты с разными целями, но есть то, что нас объединяет — мы пишем в интернете.
В онлайне всё работает несколько неуклюже. Возможно, из стилистических справочников по оформлению текстов или статьи на медиуме, вы уже знаете, что есть то, что помогает удерживать внимание читателей:
- Короткие абзацы
- Сочетание коротких и длинных предложений
- Маркированные списки
- Релевантные иллюстрации
Проблема в том, что неправильно применять эти «лайфхаки» работы с текстами вслепую.
Врачи изучают строение человеческого тела перед тем, как его лечить. Авторам следует изучить, как работает человеческий глаз, чтобы побуждать людей поглощать контент. Давайте посмотрим, как люди читают сегодня, чтобы узнать, как писать для них.
Научная основа этой статьи
Nielsen Norman Group — одна из наиболее известных компаний, которая исследует пользовательский опыт. У них есть, что сказать о том, как люди читают в интернете. Эта статья основана на их данных из экспериментов по отслеживанию движения глаз.
Концепция «сканирования»
Что такое сканирование? Это когда люди быстро просматривают слова, фразы, заголовки или разделы страниц.
Скорее всего они сканируют цифровой контент, а не читают его. Это не ваша вина. Вы можете быть ещё одним Львом Толстым и написать «Анну Каренину 2.0», но интернет беспощаден к текстам.
NN Group выяснили, что 79% людей постоянно сканируют любую новую страницу, которую видят. И только 16% читают на странице каждое слово.
Сканирование — поиск. Может показаться, что такое поведение читателя обусловлено ленью, но это не так. Это эффективная стратегия поиска и фильтрации информации. Сканирование также позволяет людям избежать информационной перегрузки.
Как понять, что вы сканируете?
- Вы фиксируется взгляд на отдельных словах, но не на всей строке текста
- Вы обрабатываете контент нелинейным образом — пропускаете некоторые части, чтобы найти нужную вам информацию
- Вероятно, вы просканируете этот текст. Для меня это абсолютно нормально
9 паттернов сканирования
Насколько мне известно, специалисты Nielsen Norman Group были первыми, кто открыл и исследовал паттерны сканирования. Они надевали на головы людей камеры и наблюдали, как визуально они воспринимают цифровые страницы с текстом и изображениями. Это похоже на использование Hotjar, но для глаз. Ниже я приведу наиболее распространенные паттерны сканирования, которые они обнаружили.
F-паттерн (F-pattern)
Если мы читаем слева направо, мы сканируем текст следующим образом:

Мы смотрим на первые слова в каждой строке текста и часто просматриваем больше слов в первых строках. По мере продвижения вниз по странице, мы читаем всё меньше слов в каждой строке и только слова, ближайшие к левому краю:
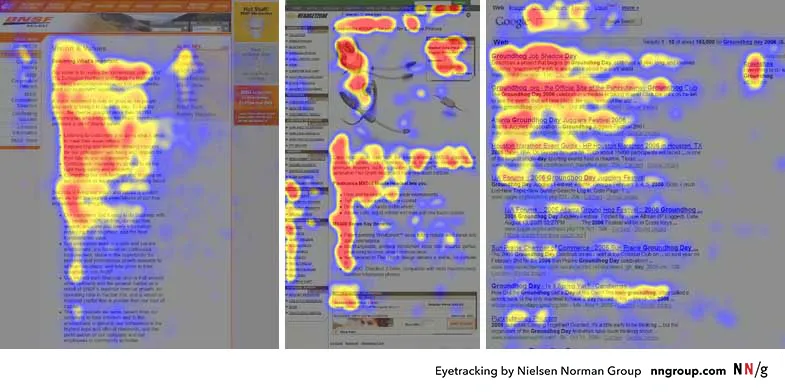
В языках, где чтение происходит справа налево, как, например, в арабском, F-паттерн отображается зеркально:
Паттерн «слоёный пирог» (Layer-cake pattern)
Часто люди читают / ищут / сканируют только подзаголовки (h2):

Этот способ чтения помогает найти и выделить темы на странице. Люди читают разделы, которые считают полезными и игнорируют текст с неинформативными заголовками.

Краткие, информативные подзаголовки помогают читателям быстро находить необходимую информацию и сохранять концентрацию при чтении длинного текста. Поэтому лучше делать подзаголовки чёткими, нежели интересными или остроумными.
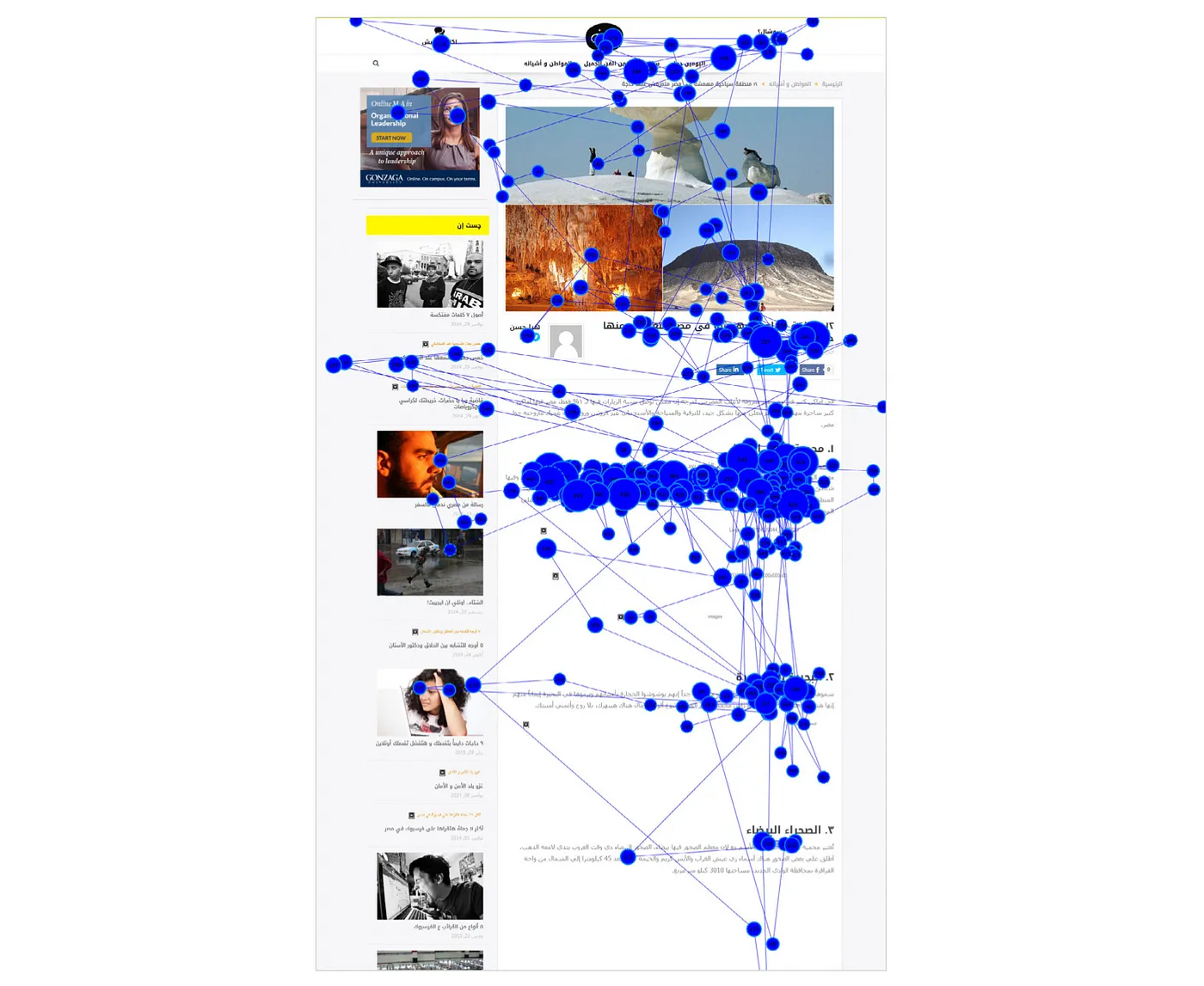
Пятнистый паттерн (Spotted pattern)
Иногда читатели сканируют текст, чтобы найти ключевые слова:

Например, здесь человек преимущественно искал и просматривал числовые данные:

Пятнистый паттерн свидетельствует о том, что паттерны сканирования — неслучайность. Читая в интернете, все мы подсознательно ищем ключевую информацию. Нет такого понятия, как чтение статей для удовольствия, за исключением, возможно, чтения The New Yorker.
Полное ознакомление (Commitment pattern)
Редкая жемчужина. Если вас интересует определенный подзаголовок (h2), вы прочитаете весь текст под ним:

Этот паттерн подразумевает, что люди читают все строки под интересующим их разделом. Это ещё одна причина делать подзаголовки релевантными.
Да, я должна была упомянуть это раньше — это действительно важно — но я спрячу этот факт здесь, для самых «преданных» авторов, которые используют паттерн «Полное ознакомление». Когда люди читают онлайн, они не просто сканируют — они ищут ответы. Они читают не для того, чтобы получить удовольствие, а чтобы найти информацию для решения задачи, которая сидит у них в голове. Как приготовить песочное печенье? Почему я так зациклен на мнении других людей? Когда родилась Елизавета II? Вопросы, вопросы… Текст должен давать ответы.
Ок, паттерн «Полное ознакомление». Он возникает только тогда, когда читатели находят раздел, который непосредственно связан с их задачей, темой или интересом. Это часто встречается в рецептах. Человек может прекратить сканировать после того, как нашёл нужную информацию, или поблуждать взглядом ещё немного.

Паттерн «Полное ознакомление» не вызывает негативных эмоций, в отличие от своего аналога — паттерна исчерпывающего обзора.
Паттерн исчерпывающего обзора (Exhaustive review pattern)
Студенты, которые готовятся к экзаменам, читают страницы, применяя этот паттерн. Копирайтеры, которые просматривают тестовые задания других копирайтеров, читают таким же образом:

В теории паттерн исчерпывающего обзора выглядит заманчиво, но никогда не приносит пользы. Он требует много энергии, а также постоянного перемещения взгляда вперёд и назад между строками. Исчерпывающий обзор имеет место быть, когда:
- Текст трудно обрабатывать, но его нужно прочитать из-за внешних обстоятельств, например, перед экзаменом
- Тема текста не соответствует уровню экспертизы читателя
- Информации не хватает, но читатели надеются её найти, как в плохо написанном разделе «Часто задаваемые вопросы» или плохих инструкциях
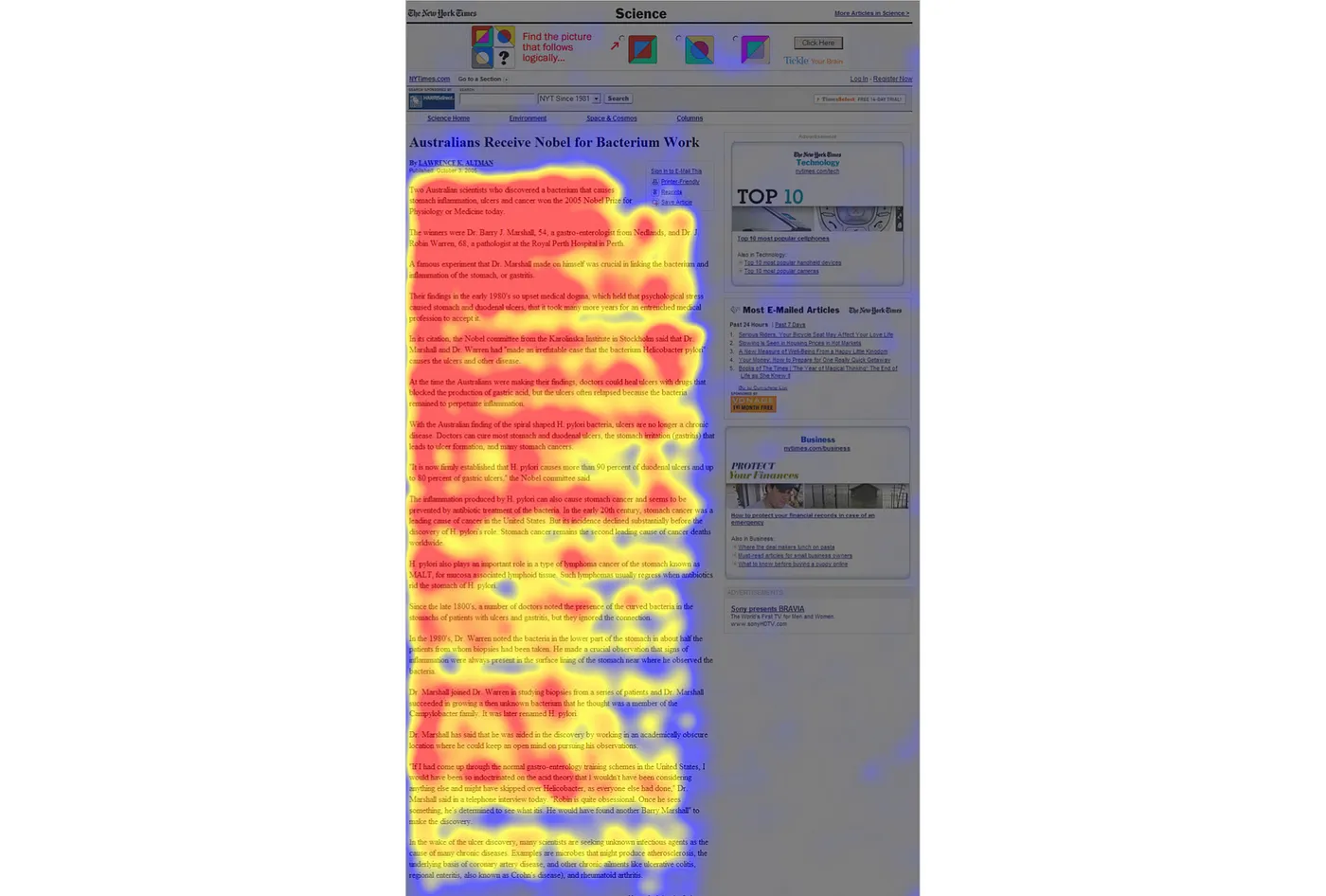
Читатели часто испытывают затруднения с тем, чтобы найти или усвоить написанную информацию. Они вынуждены возвращаться назад намного чаще, чем в случае, если они используют паттерн «Полное ознакомление». Паттерн исчерпывающего обзора — источник безысходности и разочарования.
Паттерн пропуска текста в пользу списка (List bypassing pattern)
Возникает, когда читатель пропускает текст, чтобы прочитать только список:

Паттерн пропуска текста в пользу списка также означает, что читатели пропустят первые слова каждой строки, если они очень похожи.
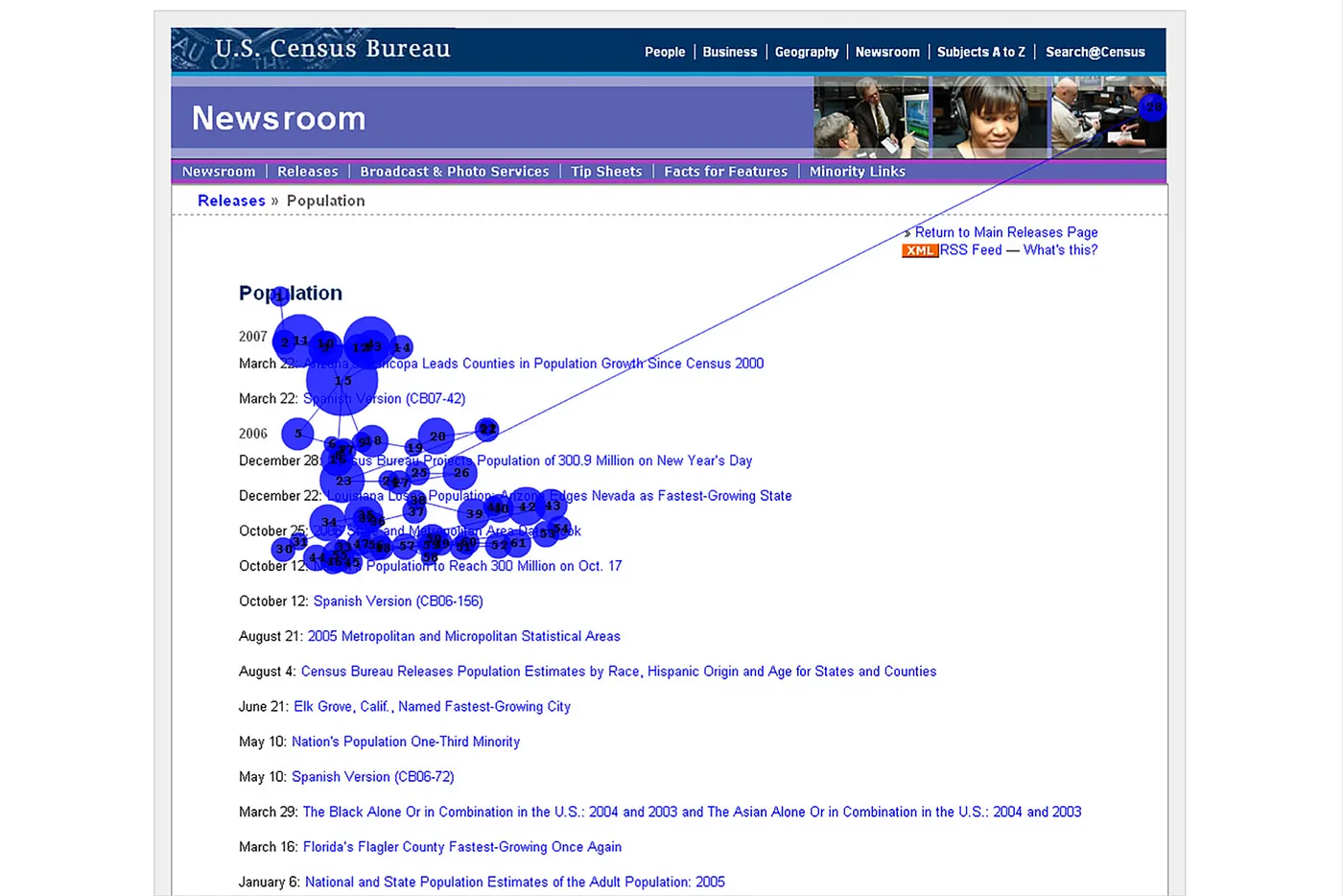
Nielsen Norman Group утверждает, что читатели часто пропускают слова «почему» и «как» при сканировании списков с часто задаваемыми вопросами.
Паттерн пропуска раздела (Section bypassing pattern)
Читатели также могут пропускать целые разделы страницы:

Такое часто происходит, когда тексты обладают низкой ценностью для читателя. Паттерн пропуска раздела напоминает F-паттерн сканирования за исключением того, что читатели едва замечают строки:
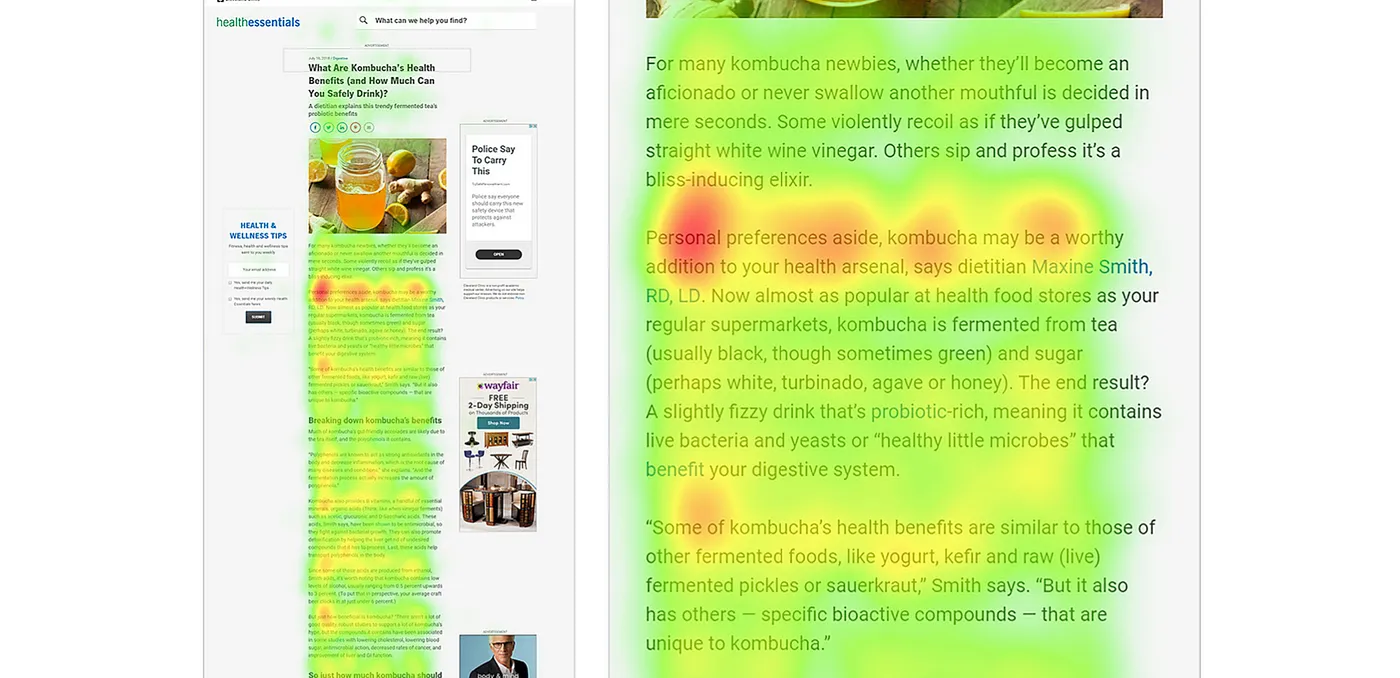
Паттерн «газонокосилки» (Lawnmower pattern)
Этот паттерн связан не столько с текстом, сколько с контентом сайта в целом. Если страница разделена на блоки с контентом — изображения, видео, тексты — наши глаза двигаются по закономерному паттерну (да, как будто вы подстригаете газон):
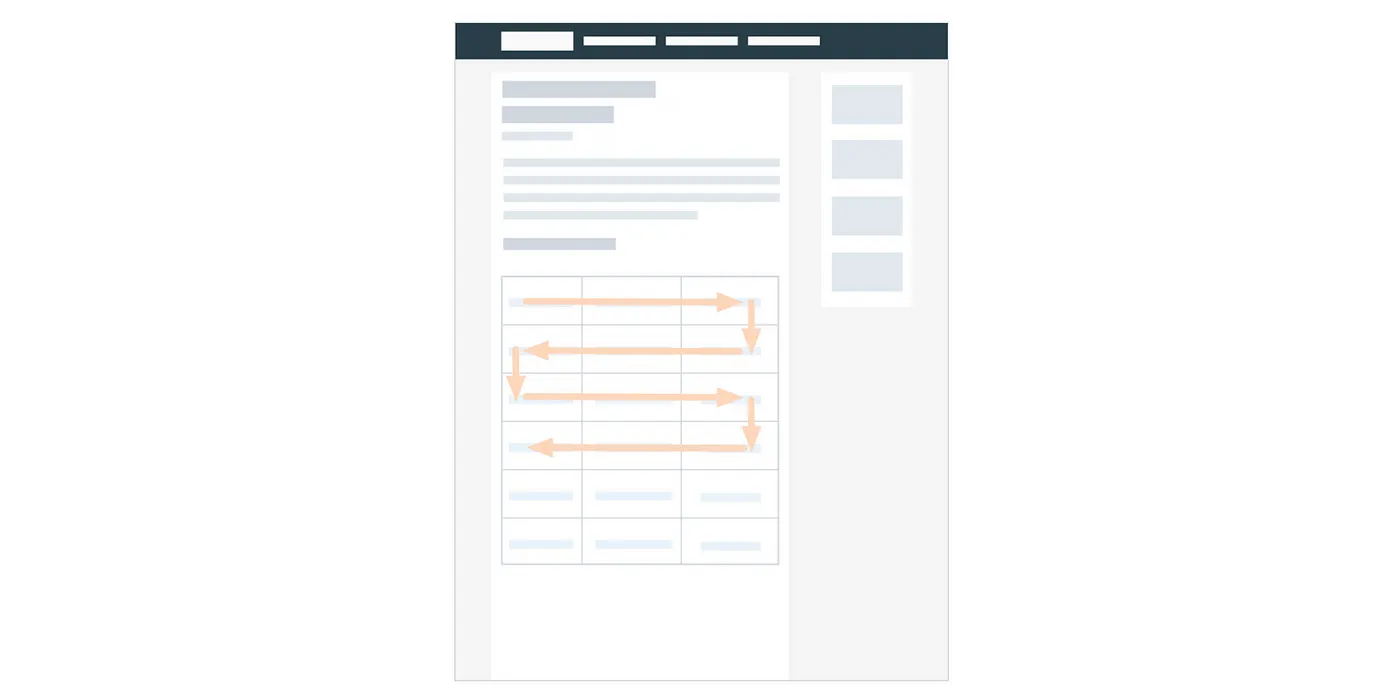
Страница с часами Apple Watch ниже — отличный пример того, как выглядят, что представляют собой «блоки» контента и как они соотносятся с паттерном «газонокосилки»:

Зигзаг-паттерн (Zigzag pattern)
Этот паттерн встречается на страницах с текстом и небольшими отрывками текста или изображениями, расположенными сбоку:
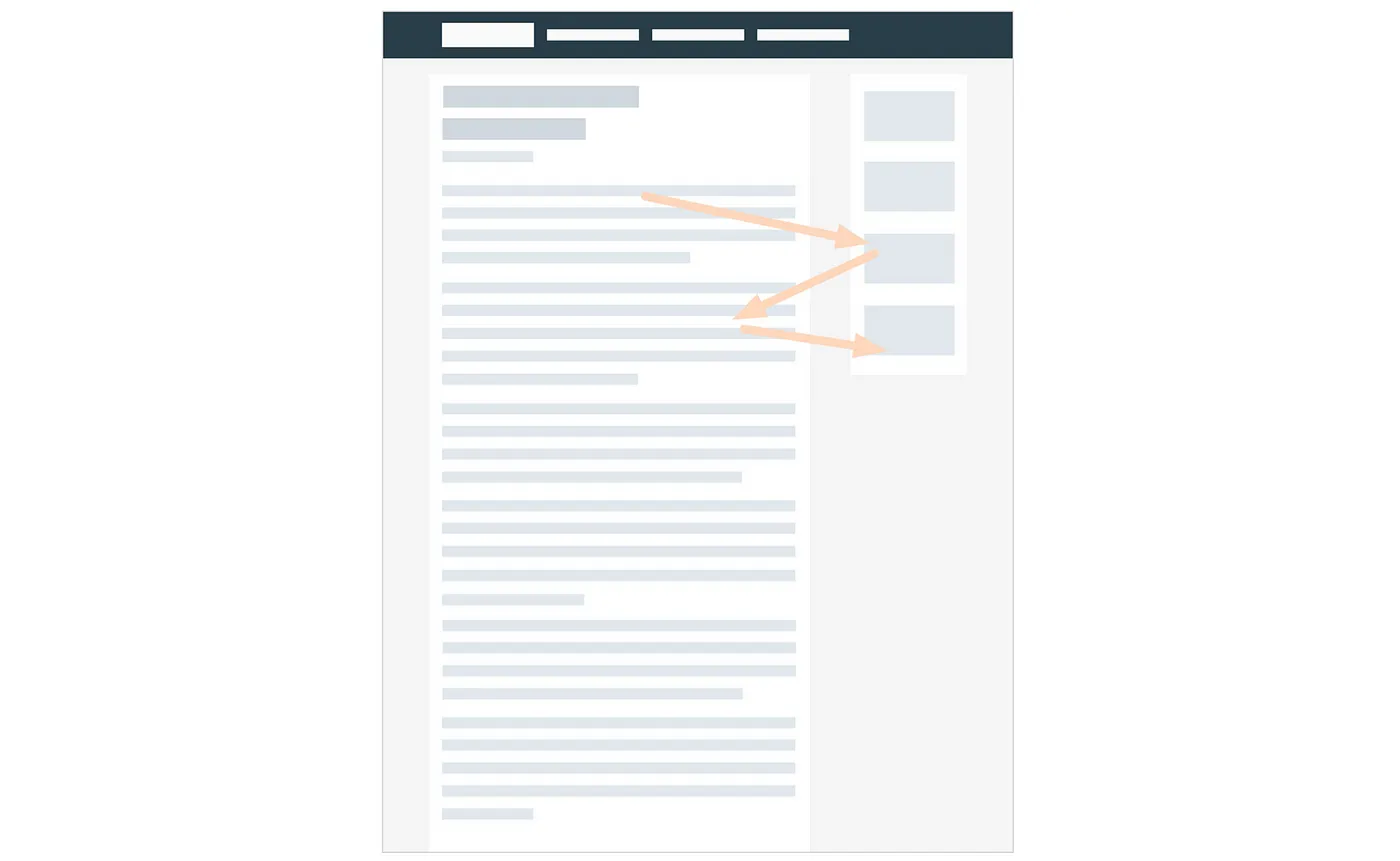
Почему люди сканируют зигзагообразно? Им либо интересны изображения, либо они сбиты с толку текстом/изображениями.
10 способов сделать текст максимально удобным для восприятия
На базе личного опыта и особенностей работы глаз, я бы порекомендовала 10 способов адаптировать контент для сканирования:
- Используйте заголовки и подзаголовки, которые отражают суть текста. Сделайте процесс поиска информации более удобным для людей, и они будут вам благодарны
- Основное сообщение предложения/пункта вынесите в первые три слова. Помните об F-паттерне
- Используйте жирный шрифт для ключевых слов или выделяйте их другими способами. Но не переусердствуйте, потому что это может запутать людей. Если вы выделите всё, то не выделите ничего
- Маркированные списки работают! К сожалению, только в случае, если пунктов менее 4-5
- Также эффективно использовать простой язык, и теперь вы знаете почему: пишите текст для аудитории с минимальной экспертизой, чтобы как можно больше людей его прочитали. Это также снижает необходимость возвращаться к предыдущим пунктам, что может утомлять
- Не переусердствуйте с введением. Это тоже моя слабость… Быстрее переходите к ключевым, структурированным, информативным и кратким блокам. Длинное вступление сигнализируют о том, что вам особо нечего сказать
- Используйте стиль «перевернутой пирамиды». Это значит — размещайте наиболее важную информацию вначале (кто, что, когда, где и почему). Затем предоставьте детали и личный опыт. В конце укажите на менее важные данные (например, мнения). Или сделайте резюме основных пунктов статьи. Это тоже работает. Как, например, здесь? Это всего лишь краткое повторение паттернов, о которых я писала выше.
- Используйте числительные, если ваш потенциальный читатель будет искать числовую информацию. Если вы пишите статью о гепардах, вместо того, чтобы написать, что они разгоняются со скоростью «восьмидесят км/ч», укажите числовое значение — 80 км/ч.
- Добавляйте глаголы. По моему опыту люди лучше воспринимают предложения с глаголами. Также не делайте, как я, и используйте неопределенную форму чаще, чем причастие.
- Изучите тему. Проведите собственные исследования. Тексты с невнятным содержанием — не то, что вам нужно. Люди приходят за информацией, а не за тем, чтобы восхищаться вашим стилем письма. Убедитесь, что проверили факты в надёжных источниках, потому что на кону стоит ваша репутация.
Обсуждение
Похожее
Прокачиваем Самокат: глава вторая
Заказываем подарочный сертификат в Sunlight
Схемы верстки от NASA