
Далее текст от лица автора
Дополненная реальность способна перенести действия и информацию из цифровой среды в реальный мир. Но какие парадигмы интерфейса могут помочь осуществить это? Вот некоторые предположения и ориентиры для дальнейшего изучения.
Чтобы система дополненной реальности могла обеспечить цифровое взаимодействие с реальным миром ей, вероятно, потребуется способность:
- Распознавать объекты в реальном мире
- Выбирать объекты в реальном мире
- Выбирать и выполнять действия с выбранными объектами
- Получать результаты на основе этих действий
Конечно, можно добавлять цифровые объекты в реальный мир и взаимодействовать с ними, но это уже затрагивает сценарии использования смешанной реальности. Поэтому, чтобы не усложнять, я не буду фокусироваться на создании и управлении цифровыми объектами… думайте больше об AR (Augmented realty — дополненная реальность), чем о VR (Virtual realty — виртуальная реальность).

MR (Mixed realty — смешанная реальность) — реальный мир, цифровые объекты
AR (Augmented realty — дополненная реальность) — реальный мир и реальные объекты, цифровая информация и цифровые действия
Варианты использования
Какие способы применения могут действительно «дополнить» реальность? То есть дать людям возможности, которых у них бы не было без включения цифровой информации и действий в физический мир. Вот несколько примеров:



Распознавание объектов
Нас повсюду окружает множество вещей. Поэтому первый шаг в распознавании объектов состоит в разделении реальности на полезные фрагменты. Модель Segment Anything компании Meta AI получила общее представление о том, что такое объекты, и может генерировать маски для любого из них на изображении или видео. В сочетании с моделью визуальных подписей, например BLIP, каждую из этих масок можно снабдить описанием. В итоге мы получим список объектов, которые находятся поблизости, и информацию о них.
Выбор объектов
Когда наше поле зрения в формате видео в реальном времени разбито на объекты, и в нём есть описания к ним, как же выбрать объект, на который мы хотим воздействовать? Один из вариантов — положиться на речевой ввод информации и использовать его для поиска описаний объектов, упомянутых выше. Представьте себе следующую ситуацию (на видео ниже), но с поиском по голосовому запросу вместо текстового.
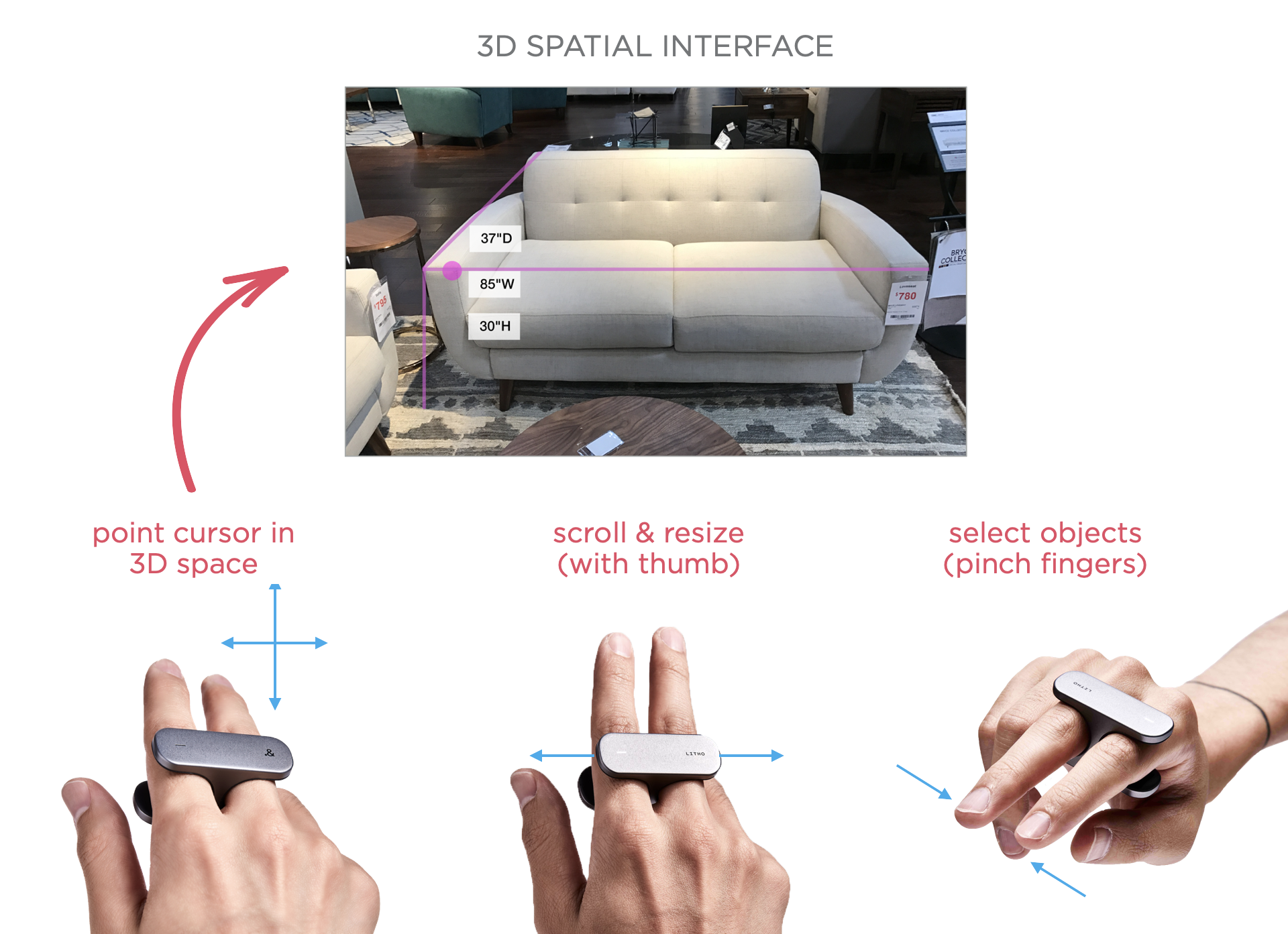
Ещё один вариант — позволить людям просто указать на объект, на который они хотят воздействовать. Для этого нужно либо отслеживать движения их рук и глаз, либо предоставить им контроллер. Именно над последним вариантом работала команда LITHO (я занимал там должность консультанта). LITHO — контроллер, который надевается на палец и позволяет выполнять интуитивные и точные жесты благодаря сенсорному покрытию снизу, настраиваемой системе тактильной обратной связи и набору датчиков отслеживания движений. По сути, он даёт возможность указывать на объекты в реальном мире, выбирать их и даже управлять ими.
Мы также можем обнаруживать и использовать направление взгляда и/или жесты рук для выбора и управления. Для конечных пользователей, это обычно означает, что им нужно будет запомнить отдельные жесты для конкретных взаимодействий вместо того, чтобы полагаться на физические элементы управления (кнопки и другие). Как видно на видео ниже, технология распознавания сложных жестов в реальном времени значительно улучшилась.
Во всех случаях необходимо сообщать людям, что их выбор принят. Есть несколько способов, с помощью которых это можно сделать: указатели, контуры, маски и многое другое.

Выполнение действий
Теперь, когда мы правильно определили и выбрали нужный объект… пришло время совершать действия. Хотя, конечно, было много обсуждений о «магазине приложений с дополненной реальностью», возможно, пришло время сосредоточиться на действиях вместо полноценных приложений. Большинство веб-сайтов, мобильных и веб-приложений содержат множество функций, многие из которых не используются. Вместо магазина, заполненного такими громоздкими контейнерами, в системе дополненной реальности можно сосредоточиться на более атомарном понятии действий: перевести, купить, поделиться.
Поскольку мы распознали и обозначили объекты, мы, вероятно, можем предположить, какие действия наиболее вероятны для каждого из них, облегчая пользователю поиск и выбор соответствующих вариантов. Разные поставщики также могут предоставлять эти действия. Подумайте: перевод с помощью Google, покупки через Amazon и так далее. Люди смогут также установить предпочтительного поставщика в качестве значения по умолчанию для конкретных действий, если выберут такую опцию «всегда использовать Wolfram Alpha для решения задач».
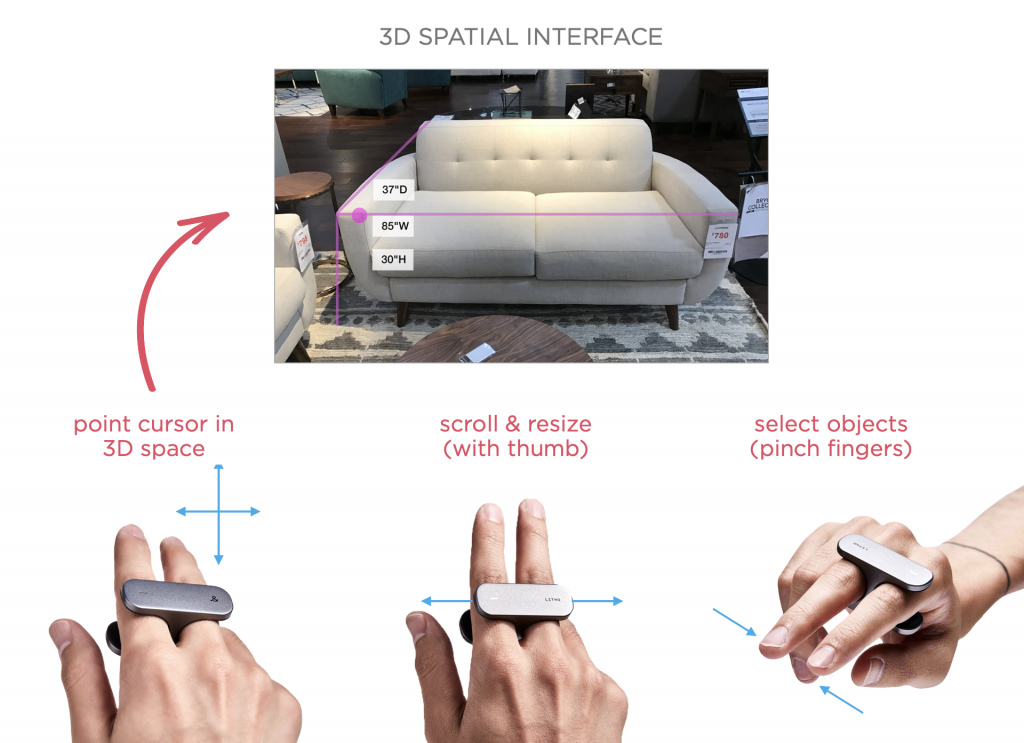
Среди всех этих доступных действий, какое же выбрать? Вновь мы можем полагаться на речь, жесты рук и/или глаз, или очень маленький портативный контроллер. И снова мне нравится явное намерение, которое выражает аппаратный контроллер: нажмите кнопку, чтобы говорить, прокручивайте его поверхность для просмотра и так далее — особенно когда он удобно расположен для управления одним пальцем.

Получение результатов
Что же происходит, когда мы воздействуем на объект в реальном мире? Мы ожидаем результатов, но каких? Лично мне не нравится идея внедрения графических элементов интерфейса (GUI) в реальный мир. Это похоже на то, что мы тащим за собой прошлое, в то время как движемся вперёд, в будущее.
Однако, непосредственное управление объектами имеет свои ограничения, поэтому, вероятно, мы ещё не полностью избавились от меню и кнопок (к сожалению).
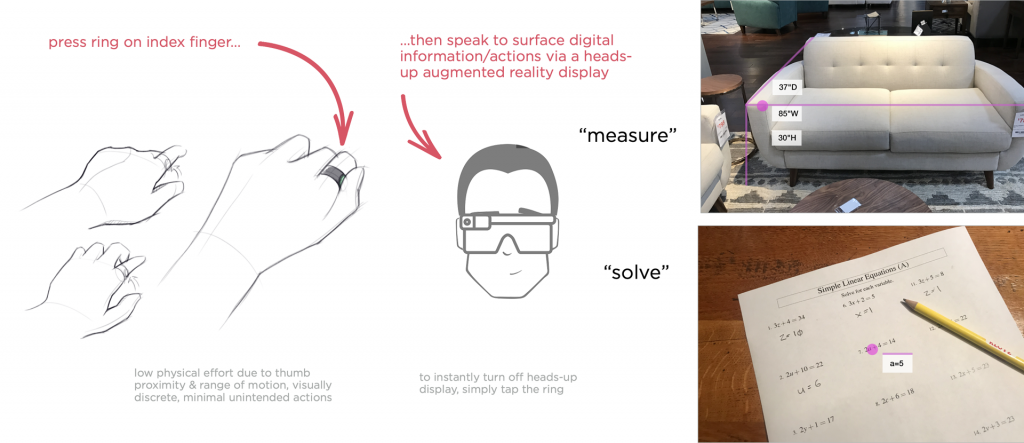
Но вернёмся в прошлое — у оригинальных Google Glass была довольно интересная функция: костный преобразователь, усиливающий звуковую информацию так, чтобы только вы могли её слышать. Вы совершаете действие с объектом и получаете аудиоответы, которые система нашёптывает вам прямо на ухо (довольно круто).
Что на самом деле будет работать лучше? Посмотрим…
Обсуждение
Похожее
12 приёмов рисования хороших эскизов сайтов и интерфейсов
Современное искусство и фотография: зачем разбираться и как понять
Как начинающему дизайнеру найти работу за рубежом