
Не прекращаются споры о том, должны ли дизайнеры писать код или нет. Тем не менее, где бы вы ни встретили этот вопрос, большинство согласятся с тем, что дизайнеры должны иметь представление о программировании: это помогает им ставить себя на место разработчиков и понимать возможности и ограничения технологий. Мыслить, выходя за рамки perfect pixel макетов. По этой же причине нужно знать и о машинном обучении.
Артур Сэмюэл в 1959 году определил машинное обучение (machine learning, ML) как область исследований, которая дает компьютерам возможность обучаться, не будучи запрограммированными напрямую (Артур Сэмюэл, 1959). Определению почти 50 лет, но только недавно мы увидели реальные технологии и как круто это может работать: виртуальные ассистенты, беспилотное управление и почта без спама — все это существует благодаря машинному обучению.
За последнее десятилетие новые алгоритмы, увеличение мощности компьютеров и возрастающий объем информации сделали машинное обучение на порядок более эффективным. Только за последние несколько лет такие компании как Google, Amazon, Apple открыли доступ разработчикам к одним из самых мощных инструментов машинного обучения. Сейчас настало идеальное время изучить машинное обучение и применить его к продуктами, над которыми вы работаете.
Почему машинное обучение важно для дизайна
Машинное обучение сейчас очень доступно, и дизайнеры могут подумать о том, как его можно применить для улучшения своих продуктов. Нам стоит научиться говорить с разработчиками о том, что можно сделать, что нужно для этого подготовить и какого результата ожидать. Ниже несколько примеров, с которых можно начать такое обсуждение.
Персонификация опыта
С машинным обучением можно анализировать поведение пользователей и настраивать продукт под них. Это позволяет выдавать рекомендации, улучшать результаты поиска, уведомления и лучше таргетировать рекламу. Например, системы рекомендаций музыкальных сервисов Spotify, Apple Music и Яндекс.Музыка используют алгоритмы машинного обучения.
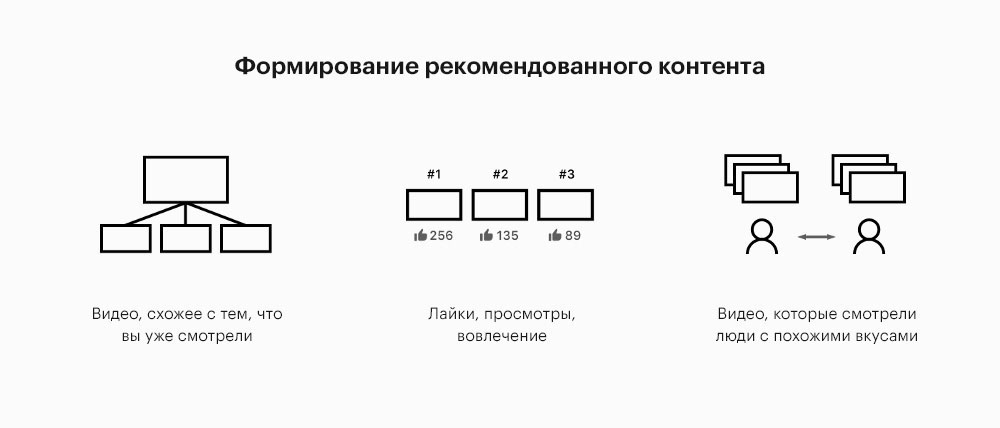
Кратко о том, как формируется рекомендованный контент.
Обнаружение аномалий
Машинное обучение эффективно при поиске аномального контента и поведения. Например, его используют для обнаружения мошенничества с платежами по кредитным картам. Сервисы электронной почты определяют спам, а социальные сети находят агрессивные высказывания.
Создание новых средств взаимодействия
Машинное обучение наделило компьютеры способностью понимать вещи, которые мы говорим (обработка текстов на естественных языках) и которые видим (машинное распознавание образов). Это позволяет Siri понимать обращение «Сири, поставь напоминание…», сервису Google Photos создавать альбомы с фотографиями вашей собаки, а Facebook описывать фотографии людям с плохим зрением.
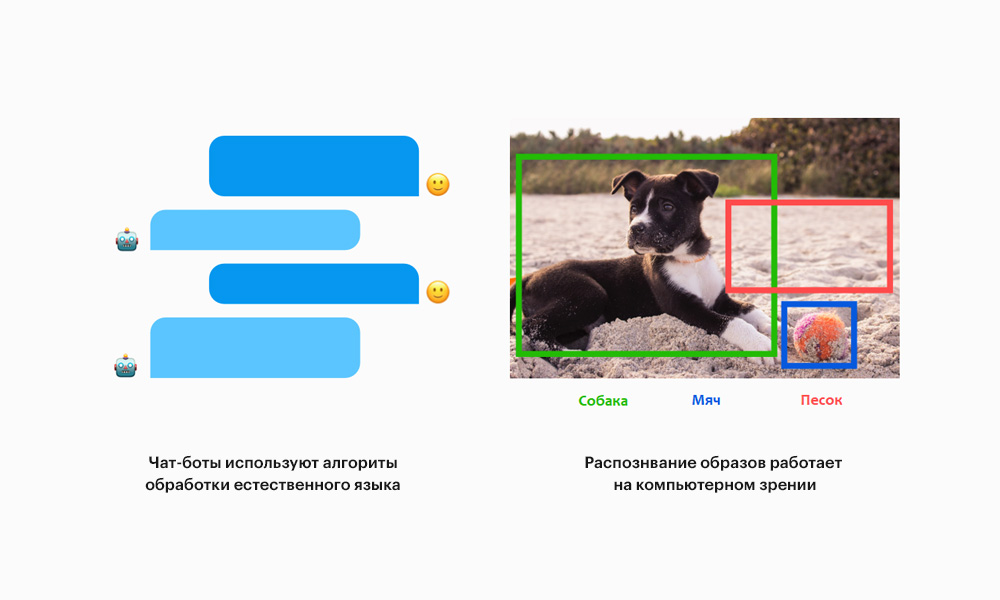
Поиск инсайтов
Машинное обучение помогает искать одинаковые предпочтения разных пользователей, объединять их в группы и анализировать более широко. Так можно оценивать популярность разных сервисов среди групп пользователей или внедрять их только людям с определенным предпочтениями.
Рекомендация контента
Машинное обучение позволяет предсказывать, какой следующий шаг сделает пользователь. Зная это, мы можем готовиться к его следующему действию. Например, если мы можем предсказать, какой контент планирует просмотреть пользователь, мы можем заранее его подгрузить, чтоб уменьшить время ожидания. «Умные ленты» социальных сетей выбирают из множества постов именно те, которые могут заинтересовать именно этого человека.
Типы машинного обучения
В зависимости от приложения и характера доступных данных, существуют различные типы алгоритмов машинного обучения. Я кратко опишу каждый из них.
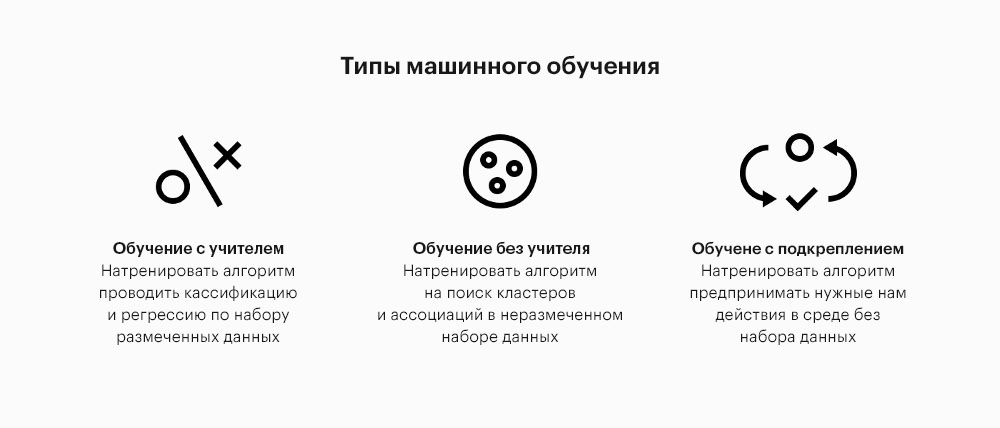
Обучение с учителем
Обучение с учителем позволяет нам делать предположения, используя корректные размеченные данные. Размеченные данные — это группа данных с присвоенными справочными тегами или выходной информацией. Например, массив фотографий котов, в котором указано, что это именно фотографии котов. Машина перемалывает такой массив данных и учится угадывать, есть ли кот на новой фотографии.
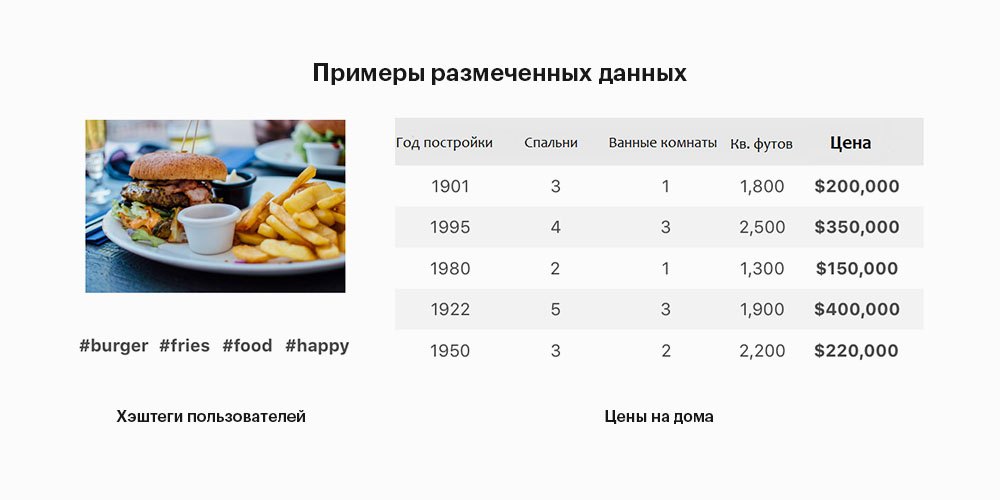
Группирование известной информации по размеченным данным может показать тенденцию, на основе которой строятся прогнозы по новым данным. Например, взглянув на новые фотографии мы можем определить, какие хэштеги им будут присвоены, а по взгляду на характеристики нового дома можем предсказать его стоимость.
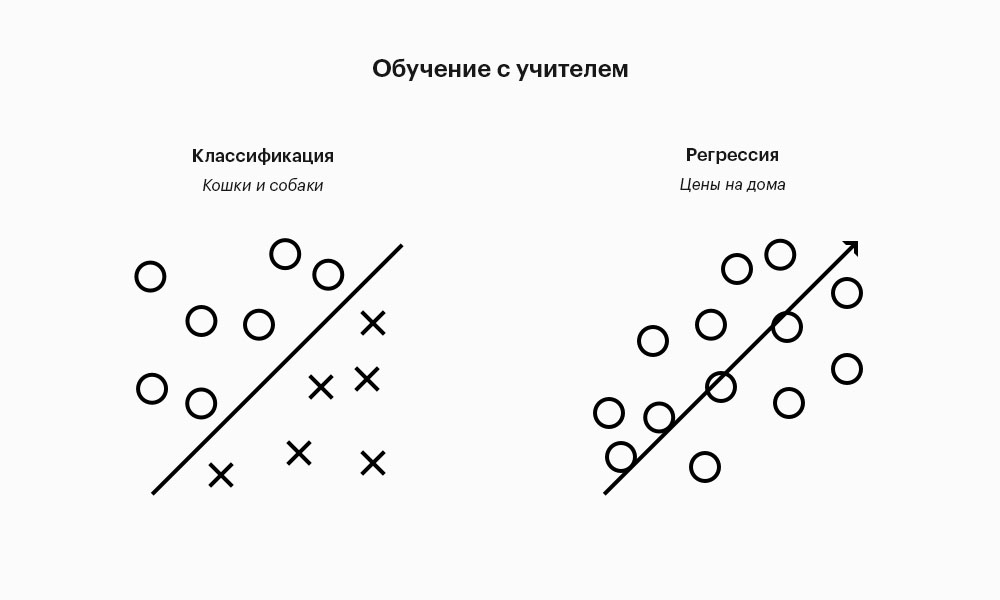
Если результат, который мы пытаемся предсказать, представляет собой список тегов или характеристик, это классификация (разделение объектов по классам). Если ожидаемый результат — это число, мы получаем регрессию (разделение по шкале, числовой или любой другой).
Обучение без учителя
Обучение без учителя используют, когда нам нечему научить машину — мы не знаем, как нужно сгруппировать объекты или какие качества объектов важны. В ходе обучения алгоритм сам сгруппирует объекты по общим характеристикам. Например, делит на кластеры товары интернет-магазина или рекомендует человеку товары на основе поведения других пользователей, которые покупали схожие с ним товары.
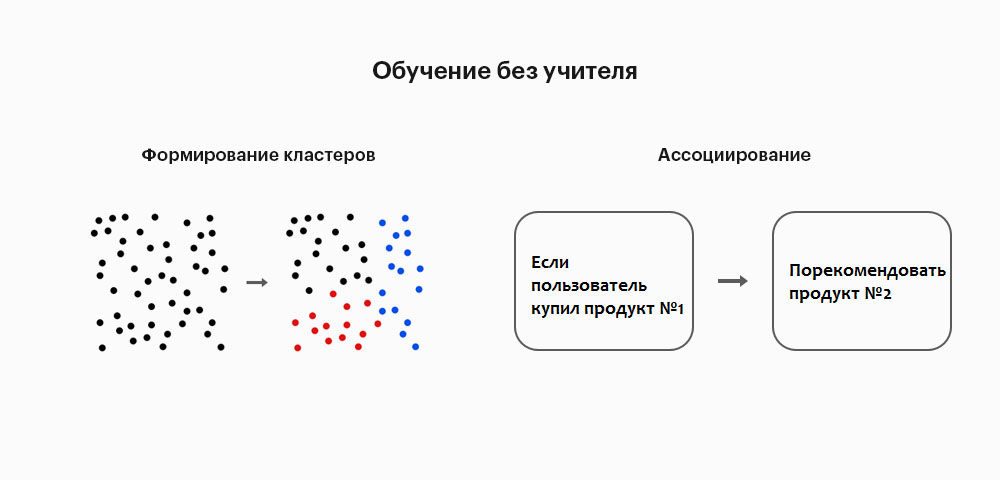
Если паттерн представляет собой группу, мы называем ее кластер. Если паттерн — это правило (например: если вот это, то вот так), мы называем его ассоциацией.
Обучение с подкреплением
Обучение с подкреплением работает вовсе без набора данных. Мы создаем агента, который собирает информацию сам, путём проб и ошибок в среде, где его стимулируют наградой. Например, агент может учиться играть в «Марио», получая положительное подкрепление за собирание монеток и негативную реакцию, если набредёт на гриб.
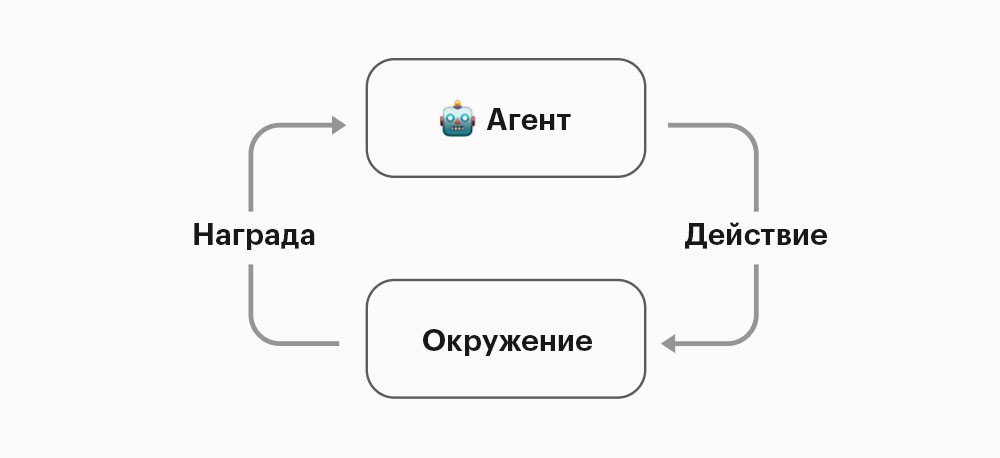
Обучение с подкреплением было подсказано методом, по которому учатся люди, и оказалось, что этот способ эффективен и в отношении компьютеров. Если точнее, подкрепление хорошо работает при обучении компьютеров играм, например, Go и Dota. (А недавно самообучающиеся боты вынесли про-игроков в Quake 3 — прим. ред.).
. . .
О чём подумать перед внедрением машинного обучения в проект
Какой подход жизнеспособен?
Понимание проблемы, которую вы пытаетесь решить, а также доступные данные будут налагать ограничения на типы машинного обучения, которые вы сможете использовать (например, определение объектов на изображениях при контролируемом обучении требует наличия размеченного массива таких изображений). Тем не менее, ограничения подхлестывают изобретательность: иногда вы можете принять решение обработать другую информацию или рассмотреть совершенно иные подходы.
Какова погрешность?
Даже несмотря на то, что машинное обучение — это наука, погрешность все равно существует. Важно принимать во внимание, как эта погрешность может повлиять на опыт пользователей. Например, когда беспилотный автомобиль перестает распознавать окружение, могут пострадать люди.
Стоит ли оно того?
Даже несмотря на то, что машинное обучение никогда не было настолько доступным как сейчас, оно все равно требует для внедрения дополнительные трудозатраты и время. Это заставляет хорошо подумать, будет ли эффект от реализации сопоставим с количеством ресурсов, которые нужно потратить.
. . .
Заключение
Мы едва-едва затронули верхушку айсберга, но надеемся, что сейчас вы чувствуете себя немного увереннее в вопросе, как можно применить машинное обучение в вашем продукте. Если вы хотите больше узнать о машинном обучении, вам могут быть полезны эти материалы:
- Machine Learning for Humans — объяснения на простом хорошем английском в сопровождении математики, кода и реальных примеров.
- Machine Learning Algorithms: Which One to Choose for Your Problem — советы для развития чутья в выборе алгоритма машинного обучения для применения к задаче.
- Machine Learning is Fun! — чуть более технический материал, который рассматривает пример внедрения машинного обучения.
- Neural Networks by 3Blue1Brown — подборка увлекательных технических видео на Youtube, которые объясняют, что такое нейронные сети и как они работают.
- Andrew Ng’s Machine Learning Course — высоко оцененный технический курс, который широко рассматривает множество тем в рамках машинного обучения.
Благодарим Вастрика за помощь в работе над переводом.
Обсуждение